1.CloudFlare与百度的矛盾
目前已知,有部分百度的爬虫会被cf挡住,所以需要去cf后台添加url规则,让百度爬虫正常通过cf防火墙,步骤如下图
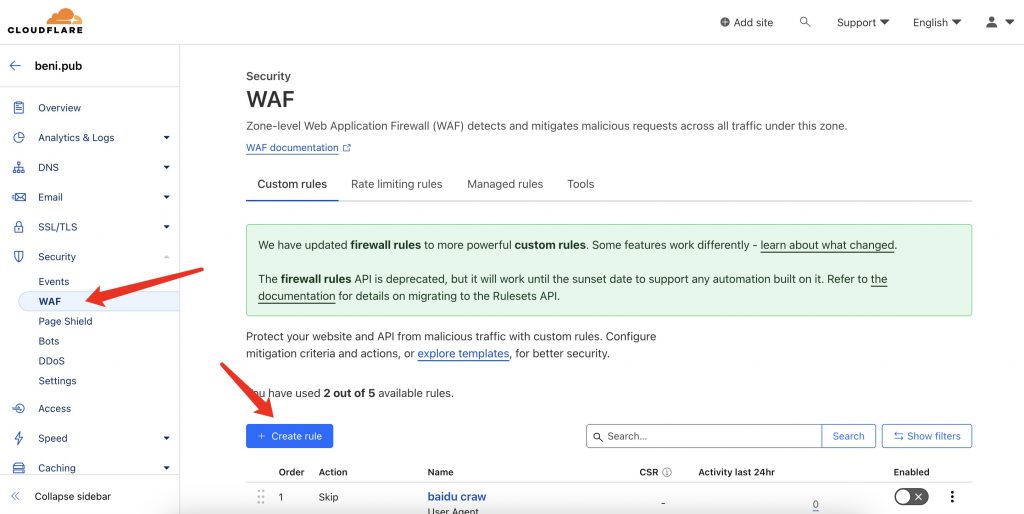
- 点击左边红色箭头的WAF按钮
- 点击右边红色箭头的 Create Rule 按钮
进入到另一个界面后,填写具体的百度rules规则,如下图
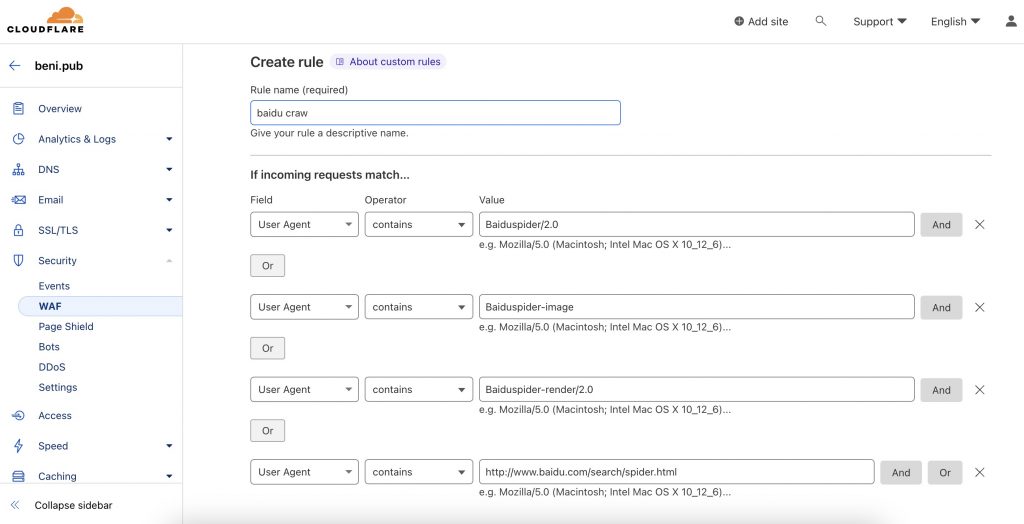
解释一下,百度爬虫会使用不同的UserAgent头去爬取数据,所以需要添加这四个。不排除以后会更新或减少。偷懒也可以直接写一个rule,value改成spider。。。后果就是所有正牌冒牌的spider都可以越过cf到你服务器了
Baiduspider/2.0
Baiduspider-image
Baiduspider-render/2.0
http://www.baidu.com/search/spider.html2.百度的robots文件检测
百度你倒是长点心,你怎么说也是国内搜索引擎的第一位。。
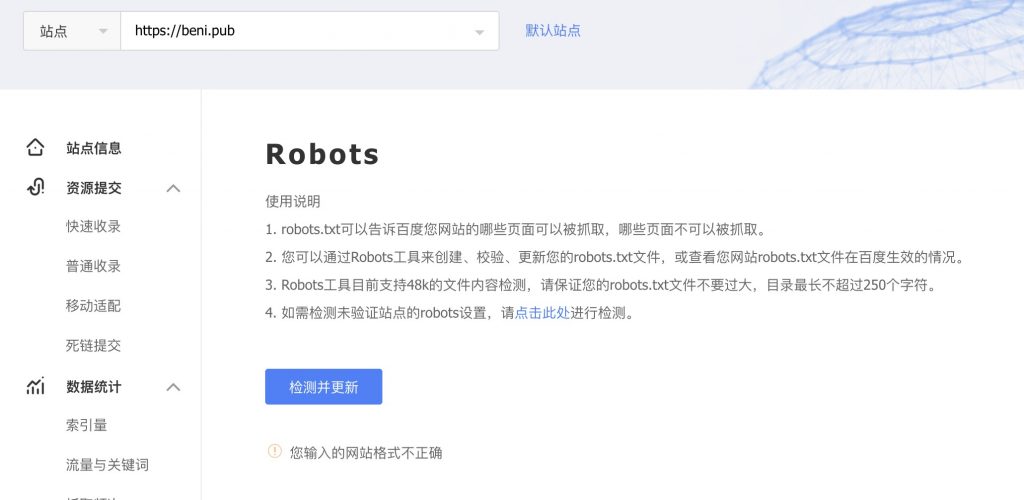
点击 检测并更新 后,居然提示。您输入的网站格式不正确
站点是要先通过你的核查才加入到站地的。。所以你这个提示到底是乱说呢,还是真的执行错误呢。。
我更倾向于是后端程序员,将一大堆错误都归类成一个错误。。导致使用者不明不白。。唉
2.1解决办法
刷新多几次就好了。。